다층 퍼셉트론(MLP)에서 수치 미분이 역전파를 대체할 수 있을까?
역전파 알고리즘 없이 딥러닝 모델을 만들 수 있을까?
정답은 "가능하다". 이번 글에서는 역전파(Backpropagation)를 사용한 모델과 수치 미분(Numerical Differentiation)을 사용한 모델, 두 가지 버전의 다층 퍼셉트론(MLP) 모델을 밑바닥부터 직접 구현 할 것이다. 구현한 모델로 MNIST 손글씨 숫자 데이터셋을 학습하여 이미지를 올바르게 분류해려고 한다.
글을 읽기 전 알아야 할 점
- 이 글에서는 딥러닝 모델을 처음부터 직접 구현하는 것이 목표이므로, Python, Numpy, Matplotlib만 사용한다.
- 수학적 개념이나 알고리즘을 깊이 있게 다루지는 않는는다.
역전파
기계 학습에서 역전파(Backpropagation)는 신경망을 학습시키기 위해 사용되는 계산법이다. 이 방법은 연쇄 법칙(Chain Rule)을 기반으로 작동한다. 역전파의 목표는 순전파에서 사용된 가중치(weight)와 편향(bias)을 업데이트하는 것이다. 가중치와 편향이 잘 학습될수록 모델의 정확도가 향상 된다. 이러한 파라미터를 업데이트하려면 각 가중치와 편향의 기울기(gradient)를 계산해야 하는데, 이때 기울기는 각 파라미터가 예측값과 실제값의 차이(오차)에 얼마나 기여했는지를 나타낸다.
오차를 계산한 후 두 가지 선택이 있는데,
- 역전파를 사용하여 가중치를 역방향으로 전파하고 각 가중치와 편향의 기울기를 계산하는 방법.
- 수치 미분을 사용하여 파라미터(가중치와 편향)를 아주 조금 변경하고, 이에 따른 오차의 변화를 관찰하는 방법.
이번 구현에서는 역전파를 사용하지 않고 수치 미분으로 모델을 학습시켜 보자!
수치 미분이란
미분의 정의
고등학교에서 배운 미분의 정의를 떠올려 보자.
- h: 매우 작은 값
- h가 0에 가까워질수록 해당 지점에서의 순간 변화율을 구할 수 있다.
수치 미분
실제 문제에서 기울기를 정확하게 계산하는 것은 어렵기 때문에, 우리는 수치 미분을 사용한다.
수치 미분의 종류:
- 전방 차분(Forward Difference):
- 후방 차분(Backward Difference):
- 중앙 차분(Central Difference, 더 정확함):
우리는 가장 정확한 방법인 중앙 차분을 사용할 것이다.
수치 미분을 모델 학습에 적용하는 방법
: 각 파라미터 x에 작은 값h를 더한 후 모델의 오차를 계산한다.: 각 파라미터 x에서 작은 값h를 뺀 후 모델의 오차를 계산한다.: 두 값을 더한 후 로 나누면 기울기가 된다. - 이 과정을 모든 파라미터에 대해 반복하여 기울기를 계산한한다.
실제 코드에 적용해보자 (feat. MNIST)
MNIST 데이터셋
- MNIST 데이터셋은 손글씨 숫자로 이루어진 데이터셋이며, 학습용 60,000개, 테스트용 10,000개의 이미지로 구성되어 있다.

모델 학습 🤖
- 수치 미분의 핵심 개념은 손실 함수의 기울기를 수치적으로 계산하는 것이다.
- 가중치와 편향 각각에 대해 아주 작은 값
h를 더하고 빼면서 기울기를 계산한다. - 예를 들어, 가중치 W1의 크기가 (784, 50)이라면, 모든 요소에 대해
h를 추가/제거하며 기울기를 구해야 하므로 39,200번(784 x 50)의 계산이 필요하다.
코드 예시
def numerical_gradient(f, y_true, x_data, params, h=1e-4):
gradients = {} # 각 파라미터(W, b)에 대한 기울기를 저장할 딕셔너리
for key in params: # 각 파라미터(W1, W2, b1, b2)에 대해 반복
param = params[key] # 현재 파라미터 선택
grad = np.zeros_like(param) # 파라미터와 동일한 형태의 기울기 배열 생성
if param.ndim == 1: # 편향 벡터의 경우
for i in range(param.shape[0]): # 각 요소에 대해 반복
temp_params = params.copy()
param_plus = param.copy()
param_minus = param.copy()
param_plus[i] += h # b_i에 h 추가
param_minus[i] -= h # b_i에서 h 감소
# 편향을 변경한 상태에서 손실 계산
temp_params[key] = param_plus
loss_plus = f(y_true, x_data, temp_params)
temp_params[key] = param_minus
loss_minus = f(y_true, x_data, temp_params)
grad[i] = (loss_plus - loss_minus) / (2 * h) # 중앙 차분 방식으로 기울기 계산
else: # 가중치 행렬의 경우
for i in range(param.shape[0]): # 행을 따라 반복
for j in range(param.shape[1]): # 열을 따라 반복
temp_params = params.copy()
param_plus = param.copy()
param_minus = param.copy()
param_plus[i, j] += h # w_ij에 h 추가
param_minus[i, j] -= h # w_ij에서 h 감소
# 가중치를 변경한 상태에서 손실 계산
temp_params[key] = param_plus
loss_plus = f(y_true, x_data, temp_params)
temp_params[key] = param_minus
loss_minus = f(y_true, x_data, temp_params)
grad[i, j] = (loss_plus - loss_minus) / (2 * h) # 중앙 차분 방식으로 기울기 계산
gradients[key] = grad # 계산된 기울기 저장
return gradients # 모든 기울기 반환테스트 결과
사전 준비
- 모델 = 다층 퍼셉트론 (MLP)
- 에폭폭 = 50
- 배치 크기 = 100
- 레이어 수 = 2 (입력층, 출력층)
- 파라미터 = 가중치 2개, 편향 2개
- 손실 함수 = 크로스 엔트로피
- 활성화 함수 = 시그모이드
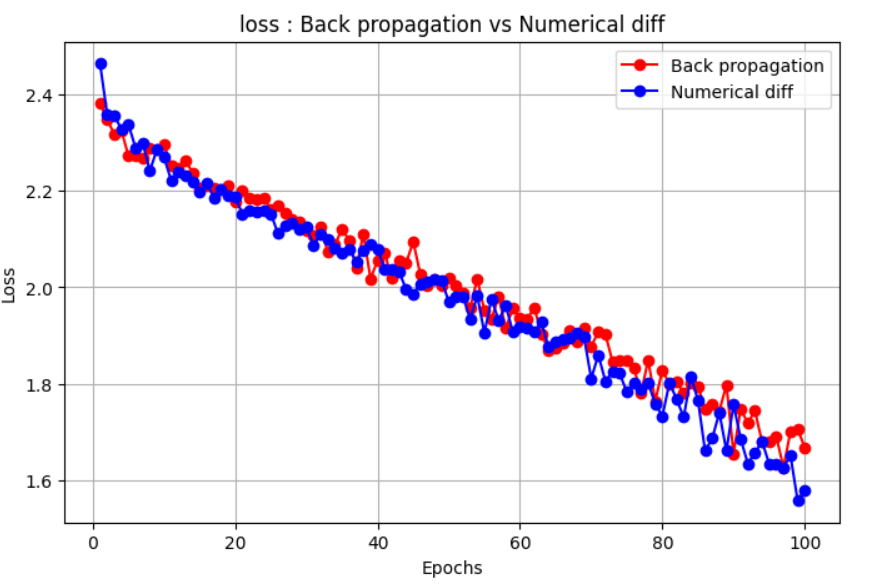
손실 값
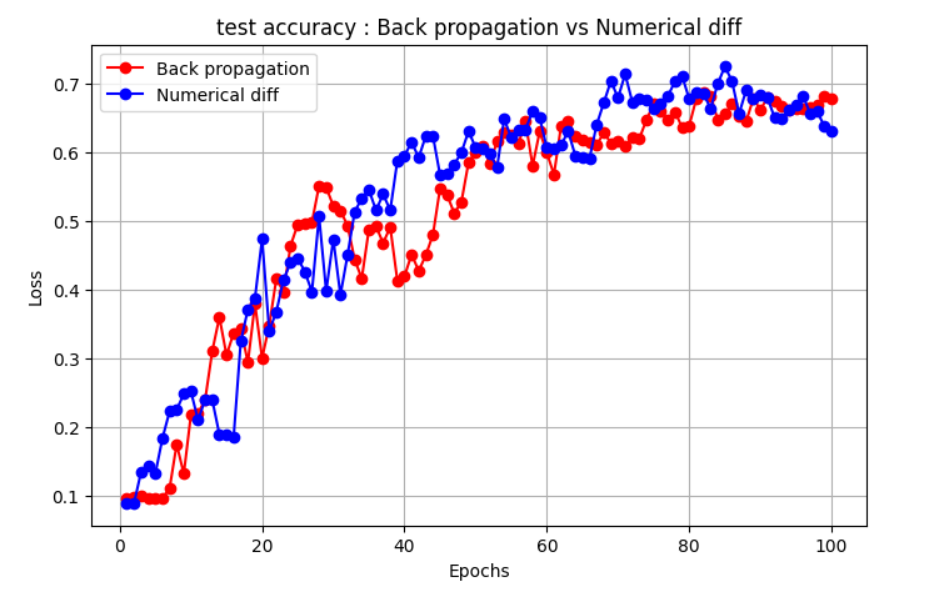
테스트 정확도
| 방법 | 에포크 ⏳ | 소요 시간 ⏱️ | 손실 📉 | 테스트 정확도 🎯 |
|---|---|---|---|---|
| 역전파 (Backpropagation) | 100 | 3.1초 | 1.6676 | 0.6783 |
| 수치 미분 (Numerical Differentiation) | 100 | 141분 55.3초 | 1.5788 | 0.6309 |
결론
수치 미분을 사용해서 손실 기울기를 계산하면 2층 모델을 학습하는 데 엄청난 시간이 걸린다는 걸 알 수 있다. 이 방법은 역전파보다 훨씬 느리지만, 복잡한 최적화 기법 없이도 최적화가 어떻게 동작하는지 이해하는 데 도움을 준다.
전체 코드를 보고 싶다면 클릭