챗봇 응답 속도 최적화 하기 (1) - DB 연결 재사용
느린 응답 속도
처음에 RAG 기능을 구현 후 테스트 도중 큰 문제에 부딪혔다.
문제는 바로 ‘응.답.속.도.’
응답 속도가 느려도 너무 느렸다. 얼마나 느린지 살펴볼까?
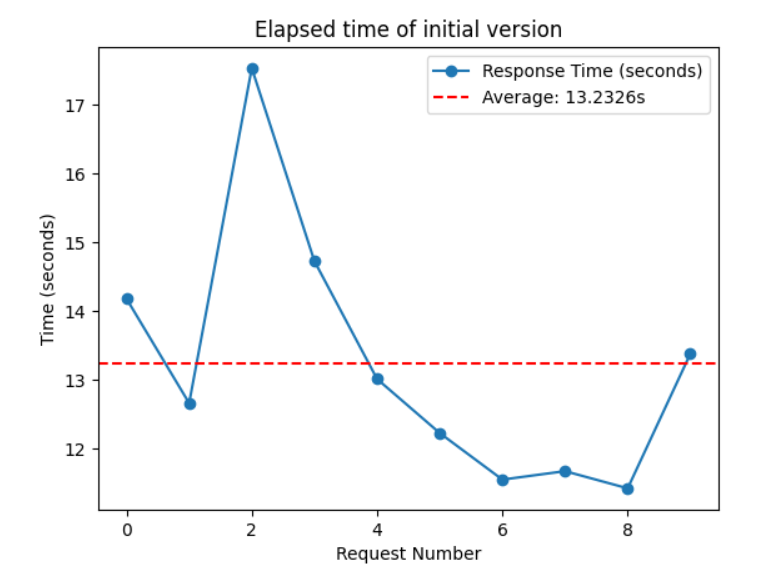
API 10번 요청 기준 평균 응답 시간 : 13.2326 sec
응답속도가 느리니 다음과 같은 문제가 발생했다.
답변이 느려서 기다리다가 에러가 생겼다고 생각하여 질문을 다시 입력한다.
→ 서버 입장에서 추가 요청을 처리하느라 리소스를 소모하고, 비용이 늘어난다.
사용자들이 답답함에 챗봇을 종료한다.
→ 사용자들의 이탈률이 높으면 비즈니스에 치명적인 문제이다.
응답이 느린 원인
1) 벡터 데이터베이스 연결
- 문제점 - 매번 요청할 때마다 데이터베이스와 새롭게 연결해서 사용한다.
- 걸리는 시간 - 평균 3초
- 해결 - AI 서버가 처음 시작될 때 데이터베이스를 연결한 후 요청할 때마다 재사용한다.
2) LLM 모델
- 문제점 - LLM모델이 답변을 완성할 때까지 기다렸다가 답하기 때문에 속도가 매우 오래 걸린다. 답변의 길이가 길어질 수록 전체 처리 시간이 길어진다.
- 걸리는 시간 - 답변의 길이에 따라 다르다. 짧으면 3초도 걸리지만 길면 10초 넘게 기다린다.
- 해결 -
응답 스트리밍도입
3) Lambda 서버의 콜드 스타트 이슈
- 문제점 - AWS Lambda 서버는 요청이 들어올 때 인스턴스가 켜지고, 응답 후 재요청이 없으면 인스턴스가 종료된다. 즉, 오랫동안 서버에 요청이 없다가 갑자기 들어오면 서버가 켜지는데 오랫동안 기다려야 한다.
- 걸리는 시간 - 약 30초
- 해결 -
AWS Eventbrige를 활용해 5분에 한 번씩 요청 보내서 인스턴스 유지하기
첫번째 이슈부터 해결해보자
벡터 데이터베이스 연결 재사용하기 (feat. lifespan)
이번 글에서는 FastAPI의 **Lifespan**을 이용해 데이터베이스를 연결하는데 걸리는 시간을 없애는 방법을 알아보자!
![]()
FastAPI는 현대적이고, 빠르며(고성능), 파이썬 표준 타입 힌트에 기초한 Python의 API를 빌드하기 위한 웹 프레임워크입니다.
FastAPI Lifespan
- 애플리케이션이 시작될 때 한 번, 끝날 때 한 번 실행되는 로직
- Lifespan은 앱에서 한 번만 실행되고 매번 요청 때마다 계속 재사용되는 작업에 매우 유용하다.
- 예시 - 데이터베이스, 머신러닝 모델
Lifespan 적용해보기
- lifespan을 이용해서 애플리케이션이 시작할 때 벡터 데이터베이스를 연결한다고 가정해보자!
- 먼저
main.py에 아래처럼vector_store을lifespan함수에 실행을 하고@asynccontextmanager라는 데코레이터로 감싼다.
python
# main.py
from contextlib import asynccontextmanager
from fastapi import FastAPI
vector_store = None
@asynccontextmanager
async def lifespan(app: FastAPI):
# Load the Vector store when appication is initialized
global vector_store
vector_store = 1
print("vector store initialized")
print("vector_store: ", vector_store)
yield
# Clean up vector store and release the resources
vector_store = None
app = FastAPI(lifespan=lifespan)
@app.get("/")
def read_root():
return {"message": "Welcome to the chatbot API!"}
if __name__ == "__main__":
APPLICATION_PORT = 8000
uvicorn.run("app.main:app", host="127.0.0.1", port=APPLICATION_PORT, reload=True)main.py를 실행 결과
python
INFO: Will watch for changes in these directories: ['C:\\Users\\Beom\\woorinara-chatbot-api']
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [10388] using StatReload
INFO: Started server process [17920]
INFO: Waiting for application startup.
vector store initialized
vector_store: 1
INFO: Application startup complete.- application이 시작할 때
vector store가 초기화되는 것을 확인할 수 있다. vector store가 전역 변수화 되었기 때문에 다른 파일에서도 사용 가능하다.
얼마나 시간이 단축되었을까?
매번 요청 때마다 vector DB 연결할 필요 없이 한번 연결하고 계속 사용하면 된다. 몇 초나 시간 단축이 되었을까?
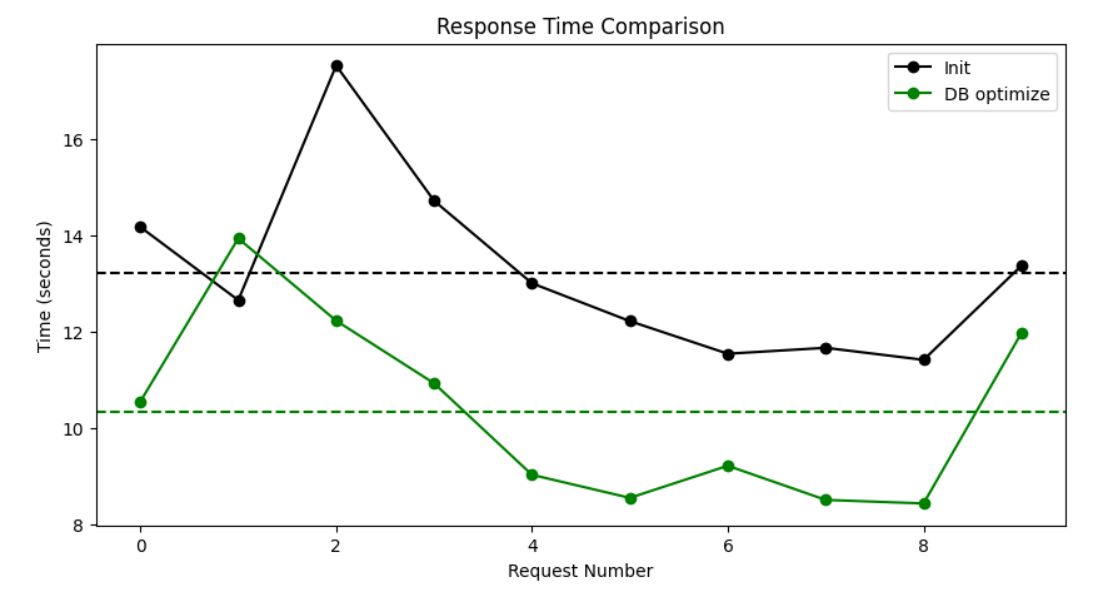
평균 응답시간 비교 (약 3초 감소)
- 기존 방법 - 13.2326 sec
- DB연결을 최적화 - 10.3380 sec
평균 10초대로 줄어든 것을 확인할 수 있다. 무려 2.8946초나 줄일 수 있다!
다음 글에서는 압도적으로 시간을 많이 줄일 수 있는 방법이 있으니 궁금한 사람들은 다음 글에 이어서!